

2026년 2월, 슈퍼볼 광고판이 뜨겁게 달아올랐다. Anthropic이 GPT의 광고 모델을 저격하는 광고를 내보냈고, Opus 4.6을 출시하고 불과 1시간 뒤 Sam Altman이 반격했다. Claude Opus 4.6이 Terminal Bench 2.0에서 65.4%를 기록하며 1위를 차지한 지 한 시간 만에, OpenAI가 GPT 5.3 코덱스를 발표하며 77.3%로 역전했다.
같은 날 출시된 두 AI 모델. 개발자 커뮤니티는 순식간에 비교 논쟁으로 뜨거워졌다. 하지만 벤치마크 점수만으로는 전체 그림이 보이지 않는다. 직접 돌려보니 보였던 것들이 있다.
1시간 만에 뒤집힌 1위 자리
Anthropic이 Claude Opus 4.6을 발표했을 때, Terminal Bench 2.0 점수는 65.4%였다. 에이전틱 코딩 분야에서는 당시 최고 점수였고, 발표 자료에는 자신감이 넘쳤다. 그런데 슈퍼볼 광고가 문제였던 모양이다. GPT의 광고 모델을 노골적으로 저격하는 내용이었거든.
딱 1시간 뒤, Sam Altman이 트윗을 올렸다. "We have something to show you." GPT 5.3 코덱스였다. Extra High 버전의 Terminal Bench 2.0 점수는 77.3%. 역대 최고 점수였고, Opus가 겨우 1시간 동안 지켰던 1위 자리는 순식간에 넘어갔다.
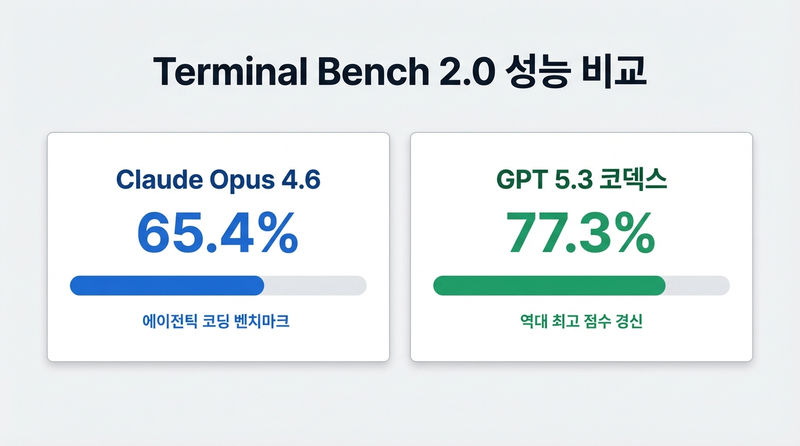
약 12% 점프는 작은 숫자가 아니다. OpenAI가 에이전틱 코딩 분야에 얼마나 공을 들였는지 보여주는 수치다. Reddit의 r/LocalLLaMA 게시판은 그날 밤새 비교 포스트로 도배가 됐다.
PRD 계획 테스트 — 계획은 손실 과정이다
숫자가 큰 차이를 보인 건 Terminal Bench만이 아니었다. PRD 계획 테스트에서도 격차가 드러났다.
PRD 계획 테스트는 이렇게 진행된다. 복잡한 요구사항 문서를 주고, AI에게 계획을 세우게 한다. 그런 다음 원래 요구사항과 비교해서 얼마나 살아남았는지 평가한다. 결과는 생각보다 충격적이었다.
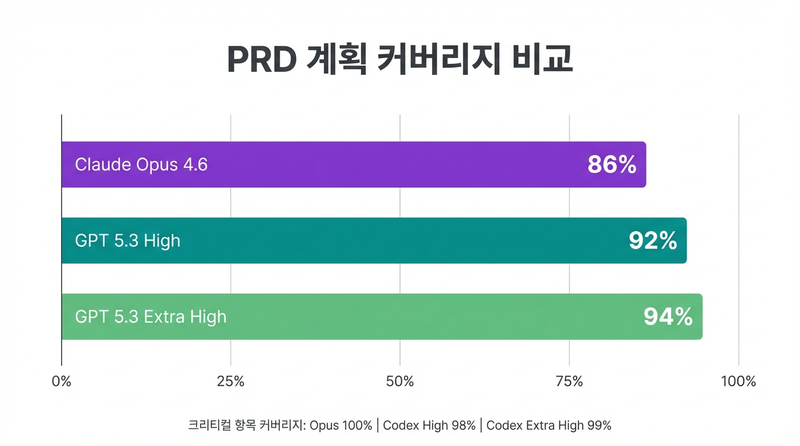
Claude Opus 4.6은 86% 커버리지를 기록했다. 이전 버전 대비 크게 개선된 수치다. 특히 크리티컬 항목 누락이 0개라는 점이 인상적이었다. 하지만 GPT 5.3 코덱스는 더 높았다.
High 버전은 92% (크리티컬 98%), Extra High는 94-95% (크리티컬 98-99%). 차이가 크지 않아 보일 수 있지만, 실무에서는 저 8-14%가 버그로 이어진다.
테스트하면서 깨달은 게 하나 있다. 계획은 손실 과정(lossy process)이다. 모든 모델이 뭔가를 빠뜨린다. 그리고 그걸 알려주지 않는다. 그래서 계획 후에는 반드시 리뷰 프롬프트를 한 번 더 돌려야 한다. 그러면 99% 근처까지 올라간다. 이건 Opus든 Codex든 똑같았다.
에이전틱 파이프라인 — 하네스가 두뇌만큼 중요하다
실전 테스트는 여기서부터가 재미있었다. 양쪽 모델에 똑같은 미션을 줬다. 리서치해서 글을 쓰고, 이미지를 생성하고, Notion에 발행하는 전체 파이프라인을 자율로 돌리는 거였다.
결과는? 둘 다 Notion에 기사를 발행하는 데 성공했다. 하지만 과정에서 차이가 드러났다.
Claude Opus는 Chrome 플러그인을 통해 ChatGPT의 이미지 생성 도구에 접근했다. 실제로 AI 이미지 생성에 성공했고, 글에 자연스럽게 삽입했다. 반면 GPT 코덱스는 이미지 생성 도구 접근에 실패했다. 대신 Pillow(커맨드라인 이미지 유틸리티)로 대체했지만, 퀄리티는 당연히 떨어졌다.
더 흥미로운 건 Extra High 모델이었다. 2시간 넘게 이미지 문제를 해결하려고 시도했다. 여러 경로를 탐색하고, 에러를 분석하고, 다른 접근을 시도하고. 근데 결국 실패했다. 이 과정을 지켜보면서 든 생각은 이거였다. 더 똑똑한 게 항상 더 효율적인 건 아니구나.
핵심 인사이트: 하네스(harness)가 두뇌만큼 중요하다. Claude Code의 생태계가 Opus에게 더 넓은 활동 범위를 제공했다. Codex가 더 똑똑한 엔지니어링 모델이었지만, 도구 접근이 제한적이었다. 그리고 Extra High의 사례처럼, 더 높은 능력이 항상 더 높은 효율을 의미하지는 않는다.
동일 앱 빌드 비교 — 코드 품질의 차이
같은 프롬프트로 똑같은 앱을 빌드하게 했다. JSX를 터미널 앱으로 변환하는 도구였다. 양쪽 결과물을 펼쳐놓고 비교했을 때, 코드 스타일의 차이가 확실히 보였다.
GPT 5.3 코덱스는 실제 JSX 파서를 구현했다. JavaScript 1,000줄, Rust 520줄. HMR(Hot Module Replacement)은 구현하지 않았지만, 파서 자체는 정확했다. 코드도 깔끔했다. 불필요한 주석이나 중복이 거의 없었다.
Claude Opus는 다른 접근을 택했다. JSX 파싱 대신 함수를 직접 호출하는 방식으로 우회했다. JavaScript 2,000줄, Rust 1,300줄. 코드량이 두 배 가까이 많았다. 대신 HMR은 구현에 성공했다. 코드 흐름은 "해결, 해결, 해결, 다음 함수, 해결" 식이었다. 작동은 하는데, 스타일은 좀 투박했다.
순수 엔지니어링 관점에서는 Codex가 더 나은 결과물을 냈다. 더 적은 코드로 더 정확한 구현. 이 부분만 놓고 보면 Terminal Bench 점수 차이가 납득됐다.
커뮤니케이션과 글쓰기 — 성격이 생긴 AI
Claude는 원래 글을 잘 썼다. Anthropic 모델의 전통적인 강점이다. Opus 4.6도 마찬가지였다. 계획 보고서를 쓸 때 "레버리지 포인트" 같은 전략적 제안을 자연스럽게 포함시켰다.
그런데 GPT 5.3 코덱스도 이번엔 달랐다. 5.2 버전을 써본 사람이라면 알겠지만, 이전에는 "기계와 대화하는 느낌"이 있었다. 답변이 정확하긴 한데, 리듬이 없었다.
5.3에서는 성격이 생겼다. 문장에 리듬이 들어갔고, 설명할 때 맥락을 더 챙겼다. 계획 보고서 작성에서는 여전히 Opus만큼 전략적 인사이트를 주진 않았지만, 대화 자체는 훨씬 자연스러워졌다.
GPT 5.3 코덱스만의 특별한 혁신
GPT 5.3 코덱스에는 이전 모델과 다른 점이 몇 가지 있다.
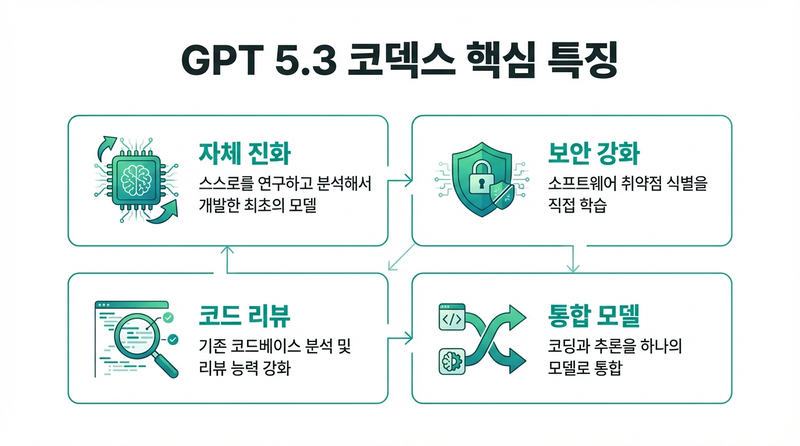
첫째, 자체 개발에 참여한 최초의 모델이다. 스스로를 연구하고 분석해서 진화했다는 얘기다. 공식 발표에서는 "self-improvement cycle"이라고 표현했다.
둘째, 코딩과 추론 모델이 통합됐다. 5.2에서는 Codex와 GPT가 분리돼 있었다. 코딩 작업을 할 때는 Codex로 전환되고, 일반 대화는 GPT로 처리되는 식이었다. 5.3에서는 하나로 합쳐졌다. 덕분에 컨텍스트 전환 없이 코드 설명과 구현을 오갈 수 있다.
셋째, 소프트웨어 취약점 식별을 직접 학습한 최초의 모델이다. 사이버 보안 분야에서 코드를 분석하고 약점을 찾는 능력이 크게 향상됐다. 코드 리뷰 능력도 뛰어나다. 실제로 "다른 모델로 코딩하고 Codex로 리뷰한다"는 워크플로우를 쓰는 사람들도 있다.
넷째, 웹 개발 UI 품질이 5.2 대비 크게 향상됐다. 디자인 디테일이나 요소 배치에서 이전보다 훨씬 세심해졌다.
해외 커뮤니티 반응 — 실제 사용자들의 목소리
Reddit의 r/ClaudeAI와 r/ChatGPT 게시판을 며칠 동안 지켜봤다. 반응은 생각보다 갈렸다.
"Codex가 Claude Code보다 좋던데 나만 그렇게 느낀 거냐?" 같은 포스트가 꽤 올라왔다. Claude Code 헤비 유저들조차 Codex의 에이전틱 코딩 성능에 놀라는 반응이었다.
한 유저는 5일 동안 똑같은 작업을 양쪽에 돌려봤다고 했다. 결론은 "Codex가 더 짧더라(더 효율적)"였다. 코드량도 적고, 목표 달성 시간도 빨랐다는 거다.
한국에서는 Codex가 상대적으로 덜 알려져 있다. Claude Code의 한국어 지원이 워낙 좋다 보니 국내 개발자들은 Opus 쪽으로 많이 쏠려 있는 편이다. 하지만 영어권에서는 논쟁이 뜨겁다.
결론 — 상황에 맞는 도구 선택이 정답
일주일 동안 두 모델을 번갈아 쓰면서 내린 결론은 이거다.
GPT 5.3 코덱스 Extra High는 순수 엔지니어링 성능에서는 가장 강력하다. Terminal Bench 2.0 점수, PRD 계획 커버리지, 코드 품질 모두 최상급이다. 하지만 Claude Code의 에이전틱 환경은 가장 뛰어나다. 도구 접근 범위가 넓고, 생태계가 잘 갖춰져 있다. 이런 AI 모델 비교에서 중요한 건 숫자만이 아니라는 얘기다.
하는 일의 성격에 따라 최적 모델이 달라진다. 복잡한 알고리즘 구현, 코드 리뷰, 보안 취약점 분석 같은 순수 엔지니어링 작업이라면 Codex가 낫다. 리서치부터 콘텐츠 생성, 외부 서비스 연동까지 포함하는 에이전틱 파이프라인이라면 Claude Code가 유리하다.
"어떤 모델이 무조건 좋다"는 생각은 현명하지 않다. 그때그때 최선의 도구를 쓰는 게 정답이다. 최첨단 모델들 간의 차이는 점점 줄어들고 있다. 결국 개발자의 실력이 더 중요하다.
AI는 곱셈기(multiplier)다. 실력 있는 개발자에게는 좋은 코드를 더 빠르게 만들어주고, 실력 없는 개발자에게는 나쁜 코드를 더 빠르게 만들어준다. 도구를 고르는 것보다, 도구를 제대로 쓸 줄 아는 게 더 중요하다는 얘기다.
'정보 > AI' 카테고리의 다른 글
| 아마존 감원 50%, 한국 직장도 위험하다 - AI 일자리 대체 현실화 (0) | 2026.02.16 |
|---|---|
| Gemini 3 Deep Think 완벽 가이드 (GPT-5와 성능 비교) (0) | 2026.02.15 |
| 클로드코드 vs AI 코딩 도구 완벽 비교 (2026년 최신) (0) | 2026.02.14 |
| NotebookLM으로 API 문서 없이 앱 만들기 (바이브 코딩 실전 가이드) (0) | 2026.02.14 |
| 개발자미래 2026 앤드류응이 예측한 생존 전략 (필독) (1) | 2026.02.13 |